加密后的数据对模糊查询不是很友好,本篇就针对加密数据模糊查询这个问题来展开讲一讲实现的思路。
为了数据安全我们在开发过程中经常会对重要的数据进行加密存储,常见的有:密码、手机号、电话号码、详细地址、银行卡号、信用卡验证码等信息,这些信息对加解密的要求也不一样,比如说密码我们需要加密存储,一般使用的都是不可逆的慢hash算法,慢hash算法可以避免暴力破解(典型的用时间换安全性)
在检索时我们既不需要解密也不需要模糊查找,直接使用密文完全匹配,但是手机号就不能这样做,因为手机号我们要查看原信息,并且对手机号还需要支持模糊查找,因此我们今天就针对可逆加解密的数据支持模糊查询来看看有哪些实现方式。
在网上随便搜索了一下,关于《加密后的模糊查询》 的帖子很多,顺便整理了一下实现的方法,不得不说很多都是不靠谱的做法,甚至有一些沙雕做法,接下来我们就对这些做法来讲讲实现思路和优劣性。
我整理了一下对加密的数据模糊查询大致分为三类做法,如下所示:
-
沙雕做法(不动脑思考直男的思路,只管实现功能从不深入思考问题)
-
常规做法(思考了查询性能问题,也会使用一些存储空间换性能等做法)
-
我们就对这三种实现方法一一来讲讲实现思路和优劣性,首先我们先看沙雕做法。
-
将所有数据加载到内存中进行解密,解密后通过程序算法来模糊匹配
-
将密文数据映射一份明文映射表,俗称tag表,然后模糊查询tag来关联密文数据
我们先来看看第一个做法,将所有数据加载到内存中进行解密,这个如果数据量小的话可以使用这个方式来做,这样做既简单又实惠,如果数据量大的话那就是灾难,我们来大致算一下。
一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间,用DES来举例,13800138000加密后的串HE9T75xNx6c5yLmS5l4r6Q==占24个字节。
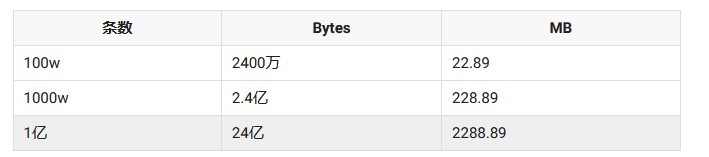
轻则上百兆,重则上千兆,这样分分钟给应用程序整成Out of memory,这样做如果数据少只有几百、几千、几万条时是完全可以这样做的,但是数据量大就强烈不建议了。
我们再来看第二个做法,将密文数据映射一份明文映射表,然后模糊查询映射表来关联密文数据,what???!!!那我们为什么要对数据加密呢,直接不加密不是更好么!
我们既然对数据加密肯定是有安全诉求才会这样做,增加一个明文的映射表就违背了安全诉求,这样做既不安全也不方便完全是脱裤子放x,多此一举,强且不推荐。
我们接下来看看常规的做法,也是最广泛使用的方法,此类方法及满足的数据安全性,又对查询友好。
在数据库实现加密算法函数,在模糊查询的时候使用decode(key) like '%partial%
对密文数据进行分词组合,将分词组合的结果集分别进行加密,然后存储到扩展列,查询时通过key like '%partial%'
在数据库中实现与程序一致的加解密算法,修改模糊查询条件,使用数据库加解密函数先解密再模糊查找,这样做的优点是实现成本低,开发使用成本低,只需要将以往的模糊查找稍微修改一下就可以实现,但是缺点也很明显,这样做无法利用数据库的索引来优化查询,甚至有一些数据库可能无法保证与程序实现一致的加解密算法,但是对于常规的加解密算法都可以保证与应用程序一致。
如果对查询性能要求不是特别高、对数据安全性要求一般,可以使用常见的加解密算法比如说AES、DES之类的也是一个不错的选择。
如果公司有自己的算法实现,并且没有提供多端的算法实现,要么找个算法好的人去研究吃透补全多端实现,要么放弃使用这个办法。
对密文数据进行分词组合,将分词组合的结果集分别进行加密,然后存储到扩展列,查询时通过key like '%partial%',这是一个比较划算的实现方法,我们先来分析一下它的实现思路。
先对字符进行固定长度的分组,将一个字段拆分为多个,比如说根据4位英文字符(半角),2个中文字符(全角)为一个检索条件,举个例子:
ningyu1使用4个字符为一组的加密方式,第一组ning ,第二组ingy ,第三组ngyu ,第四组gyu1 … 依次类推。
如果需要检索所有包含检索条件4个字符的数据比如:ingy ,加密字符后通过 key like “%partial%” 查库。
我们都知道加密后长度会增长,增长的这部分长度存储就是我们要花费的额外成本,典型的使用成本来换取速度,密文增长的幅度随着算法不同而不同以DES举例,13800138000加密前占11个字节,加密后的串HE9T75xNx6c5yLmS5l4r6Q==占24个字节,增长是2.18倍,所以一个优秀的算法是多么的重要,能为公司节省不少成本,但是话又说回来算法工程师的工资也不低,所以我也不知道是节省成本还是增加成本,哈哈哈…你们自己算吧。
回到主题,这个方法虽然可以实现加密数据的模糊查询,但是对模糊查询的字符长度是有要求的,以我上面举的例子模糊查询字符原文长度必须大于等于4个英文/数字,或者2个汉字,再短的长度不建议支持,因为分词组合会增多从而导致存储的成本增加,反而安全性降低。
大家是否都对接过 淘宝、拼多多、JD他们的api,他们对平台订单数据中的用户敏感数据就是加密的同时支持模糊查询,使用就是这个方法,下面我整理了几家电商平台的密文字段检索方案的说明,感兴趣的可以查看下面链接
-
淘宝密文字段检索方案:https://open.taobao.com/docV3.htm?docId=106213&docType=1
-
阿里巴巴文字段检索方案:https://jaq-doc.alibaba.com/docs/doc.htm?treeId=1&articleId=106213&docType=1
-
拼多多密文字段检索方案:https://open.pinduoduo.com/application/document/browse?idStr=3407B605226E77F2
-
京东密文字段检索方案:https://jos.jd.com/commondoc?listId=345
ps. 基本上都是一样的,果然都是互相抄袭,连加密后的数据格式都一致。
这个方法优点就是实现起来不算复杂,使用起来也较为简单,算是一个折中的做法,因为会有扩展字段存储成本会有升高,但是可利用数据库索引优化查询速度,推荐使用这个方法。
我们接下来看看优秀的做法,此类做法难度较高,都是从算法层面来考虑,有些甚至会设计一个新算法,虽然已有一些现成的算法参考,但是大多都是半成品无法拿来直接使用,所以还是要有人去深入研究和整合到自己的应用中去。
从算法层面思考,甚至会设计一个新算法来支持模糊查找
这个层面大多是专业算法工程师的研究领域,想要设计一个有序的、非不可逆的、密文长度不能增长过快的算法不是一件简单的事情,大致的思路是这样的,使用译码的方式进行加解密,保留密文和原文一样的顺序,从而支持密文模糊匹配,说的比较笼统因为我也不是这方面的专家没有更深一步的研究过,所以我从网上找了一些资料可以参考一下。
-
数据库中字符数据的模糊匹配加密方法:https://www.jiamisoft.com/blog/6542-zifushujumohupipeijiamifangfa.html
这里提到的Hill密码处理和模糊匹配加密方法FMES可以重点看看.
-
一种基于BloomFilter的改进型加密文本模糊搜索机制研究:http://kzyjc.cnjournals.com/html/2019/1/20190112.htm
-
支持快速查询的数据库如何加密:https://www.jiamisoft.com/blog/5961-kuaisuchaxunshujukujiami.html
-
基于Lucene的云端搜索与密文基础上的模糊查询:https://www.cnblogs.com/arthurqin/p/6307153.html
基于Lucene的思路就跟我们上面介绍的常规做法二类似,对字符进行等长度分词,将分词后的结果集加密后存储,只不过存储的db不一样,一个是关系型数据库,一个是es搜索引擎。
云存储中一种支持可验证的模糊查询加密方案http://jeit.ie.ac.cn/fileDZYXXXB/journal/article/dzyxxxb/2017/7/PDF/160971.pdf
我们到这里对加密数据的检索方案全部介绍完了,我们首先提到的是网上搜索随处可见的沙雕做法,在这里也讲了不推荐使用这些沙雕做法,尽量使用常规做法,如果公司有专业算法方向人才的话不妨可以考虑基于算法层面的超神做法。
总的来说从投入、产出比、及实现、使用成本来算的话常规做法二是非常推荐的。
原文:ningyu1.github.io/20201230/encrypted-data-fuzzy-query.html
更多文章,请关注公众号【程序员李木子】,有免费的电子书哦
