MySQL数据库开发的三十六条军规
来自一线的实战经验
每一军规背后都是血淋淋教训,不要华丽
只要实用。若有一条让你有所受益,慰矣
主要针对数据库开发人员
总是在灾难发生后,才想起容灾的重要性;总是在吃过亏后,才记得曾经有人提醒过。
一、核心军规
1、尽量不在数据库做运算
别让脚趾头想事情,那是脑瓜子的职责
让数据库多做她擅长的事:
-
尽量不在数据库做运算
-
复杂运算移到程序端CPU
-
尽可能简单应用MySQL
举例: md5() / Order by Rand()
2、控制单表数据量
一年内的单表数据量预估:
-
纯INT不超1000W
-
含CHAR不超500W
建议单库不超过300-400个表
3、保持表身段苗条
表字段数少而精:
√ IO高效 √全表遍历 √表修复快 √提高幵发 √alter table快
单表多少字段合适?
单表1G体积 500W行评估:
-
顺序读1G文件需N秒
-
单行不超过200Byte
-
单表不超50个纯INT字段
-
单表不超20个CHAR(10)字段
单表字段数上限控制在20~50个
4、平衡范式不冗余
平衡是门艺术
-
严格遵循三大范式?
-
效率优先、提升性能
-
没有绝对的对与错
-
适当时牺牲范式、加入冗余
-
但会增加代码复杂度
5、拒绝3B
数据库幵发像城市交通:非线性增长
• 拒绝3B
大SQL (BIG SQL)
大事务 (BIG Transaction)
大批量 (BIG Batch)
二、字段类军规
1、用好数值字段类型
三类数值类型:
TINYINT(1Byte)
SMALLINT(2B)
MEDIUMINT(3B)
INT(4B)、 BIGINT(8B)
FLOAT(4B)、 DOUBLE(8B)
DECIMAL(M,D)
2、将字符转化为数字
数字型VS字符串型索引
更高效、查询更快、占用空间更小
举例:用无符号INT存储IP,而非CHAR(15)
3、优先使用ENUM或SET
优先使用ENUM或SET
-
字符串
可能值已知且有限
• 存储
ENUM占用1字节,转为数值运算
SET视节点定,最多占用8字节
比较时需要加‘ 单引号(即使是数值)
• 举例
`sex` enum('F','M') COMMENT '性别'
`c1` enum('0','1','2','3') COMMENT '职介审核'
4、避免使用NULL字段
避免使用NULL字段
很难进行查询优化
NULL列加索引,需要额外空间
含NULL复合索引无效
• 举例
`a` char(32) DEFAULT NULL
`b` int(10) NOT NULL
`c` int(10) NOT NULL DEFAULT 0
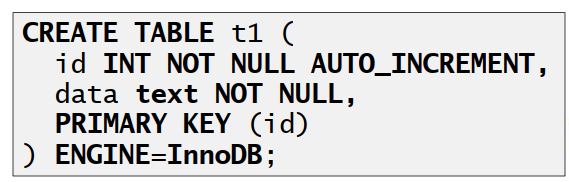
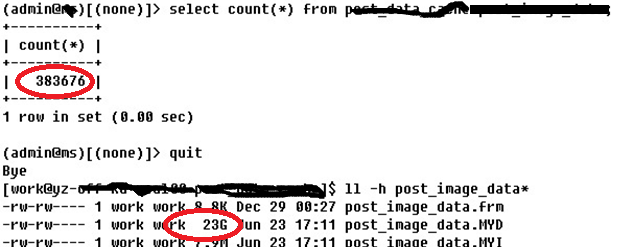
5、少用并拆分TEXT/BLOB
TEXT类型处理性能远低于VARCHAR
强制生成硬盘临时表
浪费更多空间
VARCHAR(65535)==>64K (注意UTF-8)
• 尽量不用TEXT/BLOB数据类型
• 若必须使用则拆分到单独的表
• 举例:
6、不在数据库里存图片

三、索引类军规
1、谨慎合理添加索引
谨慎合理添加索引
改善查询
减慢更新
索引不是赹多赹好
能不加的索引尽量不加
综合评估数据密度和数据分布
最好不超过字段数20%
结合核心SQL优先考虑覆盖索引
• 举例
不要给“性别”列创建索引
2、字符字段必须建前缀索引
区分度
单字母区分度:26
4字母区分度:26*26*26*26=456,976
5字母区分度:
26*26*26*26*26=11,881,376
6字母区分度:
26*26*26*26*26*26=308,915,776
• 字符字段必须建前缀索引
`pinyin` varchar(100) DEFAULT NULL COMMENT '小区拼音', KEY `idx_pinyin` (`pinyin`(8)),
) ENGINE=InnoDB
3、不在索引列做运算
不在索引列进行数学运算或函数运算
Ø无法使用索引
Ø导致全表扫描
• 举例

4、自增列或全局ID做INNODB主键
• 对主键建立聚簇索引
• 二级索引存储主键值
• 主键不应更新修改
• 按自增顺序揑入值
• 忌用字符串做主键
• 聚簇索引分裂
• 推荐用独立于业务的AUTO_INCREMENT列或全局ID生成器做代理主键
• 若不指定主键, InnoDB会用唯一且非空值索引代替
5、尽量不用外键
线上OLTP系统(线下系统另论)
外键可节省开发量
有额外开销
逐行操作
可‘到达’其它表,意味着锁
高幵发时容易死锁
• 由程序保证约束
四、SQL类军规
1、SQL语句尽可能简单
• 大SQL VS 多个简单SQL
传统设计思想
BUT MySQL NOT
一条SQL叧能在一个CPU运算
5000+ QPS的高幵发中, 1秒大SQL意味着?
可能一条大SQL就把整个数据库堵死
• 拒绝大SQL,拆解成多条简单SQL
简单SQL缓存命中率更高
减少锁表时间,特别是MyISAM
用上多CPU
2、保持事务(连接)短小
• 保持事务/DB连接短小精悍
事务/连接使用原则:即开即用,用完即关
与事务无关操作放到事务外面, 减少锁资源的占用
不破坏一致性前提下,使用多个短事务代替长事务
• 举例
发贴时的图片上传等待
大量的sleep连接
3、尽可能避免使用SP/TRIG/FUNC
• 线上OLTP系统(线下库另论)
尽可能少用存储过程
尽可能少用触发器
减用使用MySQL函数对结果进行处理
• 由客户端程序负责
4、尽量不用 SELECT *
用SELECT * 时
• 更多消耗CPU、内存、 IO、网络带宽
• 先向数据库请求所有列,然后丢掉不需要列?
尽量不用SELECT * ,叧取需要数据列
• 更安全的设计:减少表变化带来的影响
• 为使用covering index提供可能性
• Select/JOIN减少硬盘临时表生成,特别是有TEXT/BLOB时
举例
SELECT * FROM tag WHERE id = 999184
SELECT keyword FROM tag WHERE id = 999184
5、改写OR为IN()
同一字段,将or改写为in()
• OR效率:O(n)
• IN 效率:O(Log n)
• 当n很大时, OR会慢很多
注意控制IN的个数,建议n小于200
• 举例
Select * from opp WHERE phone=‘12347856' or phone=‘42242233'
Select * from opp WHERE phone in ('12347856' , '42242233')
6、改写OR为UNION
不同字段,将or改为union
• 减少对不同字段进行 "or" 查询
• Merge index往往很弱智
• 如果有足够信心:set global optimizer_switch='index_merge=off';
举例
Select * from opp WHERE phone='010-88886666' or cellPhone='13800138000';
Select * from opp WHERE phone='010-88886666' union;
Select * from opp WHERE cellPhone='13800138000';
7、避免负向查询和% 前缀模糊查询
• 避免负向查询
NOT、 !=、 <>、 !<、 !>、 NOT EXISTS、 NOT IN、NOT LIKE等
• 避免 % 前缀模糊查询
B+ Tree
使用不了索引
导致全表扫描
• 举例
MySQL>select * from post WHERE title like ‘北京%' ;
298 rows in set (0.01sec)
MySQL>select * from post WHERE title like '%北京%' ;
572 rows in set (3.27sec)
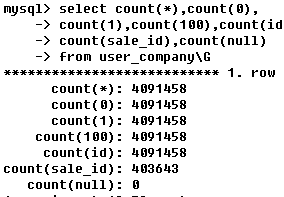
8、COUNT(*)的几个例子
• 几个有趣的例子:
COUNT(COL) VS COUNT(*)
COUNT(*) VS COUNT(1)
COUNT(1) VS COUNT(0) VS COUNT(100)
• 示例

• 结论
COUNT(*)=count(1)
COUNT(0)=count(1)
COUNT(1)=count(100)
COUNT(*)!=count(col)
• WHY?
MyISAM VS INNODB
不带 WHERE COUNT()
带 WHERE COUNT()
COUNT(*)的资源开销大,尽量不用或少用
•计数统计
实时统计:用memcache,双向更新,凌晨跑基准
非实时统计:尽量用单独统计表, 定期重算
9、LIMIT高效分页
•传统分页:
Select * from table limit 10000,10;
• LIMIT原理:
ØLimit 10000,10
偏移量越大则越慢
• 推荐分页:
Select * from table WHERE id>=23423 limit 11;
#10+1 (每页10条)
分页方式二:
Select * from table WHERE id >= ( select id from table limit10000,1 ) limit 10;
分页方式三:
SELECT * FROM table INNER JOIN (SELECT id FROM table LIMIT10000,10) USING (id) ;
分页方式四:
程序取ID: select id from table limit 10000,10;
Select * from table WHERE id in (123,456…) ;
• 可能需按场景分析幵重组索引
示例:
MySQL>select sql_no_cache * from post limit 10,10;
10 row in set (0.01 sec)
MySQL>select sql_no_cache * from post limit 20000,10;
10 row in set (0.13 sec)
MySQL>select sql_no_cache * from post limit 80000,10;
10 rows in set (0.58 sec)
MySQL>select sql_no_cache id from post limit 80000,10;
10 rows in set (0.02 sec)
MySQL>select sql_no_cache * from post WHERE id>=323423 limit 10;
10 rows in set (0.01 sec)
MySQL>select * from post WHERE id >= ( select sql_no_cache id from post limit 80000,1 ) limit 10 ;
10 rows in set (0.02 sec)
10、用UNION ALL 而非 UNION
若无需对结果进行去重,则用UNION ALL
UNION有去重开销
• 举例
MySQL>SELECT * FROM detail20091128 UNION ALL SELECT * FROM detail20110427 UNION ALL SELECT * FROM detail20110426 UNION ALL SELECT * FROM detail20110425 UNION ALL SELECT * FROM detail20110424 UNION ALL SELECT * FROM detail20110423;
11、分解联接保证高并发
• 高幵发DB不建议进行两个表以上的JOIN
• 适当分解联接保证高幵发
可缓存大量早期数据
使用了多个MyISAM表
对大表的小ID IN()
联接引用同一个表多次
• 举例:
MySQL> Select * from tag JOIN tag_post on tag_post.tag_id=tag.id JOIN post on tag_post.post_id=post.id WHERE tag.tag=‘二手玩具’;
MySQL> Select * from tag WHERE tag=‘二手玩具’; MySQL> Select * from tag_post WHERE tag_id=1321; MySQL> Select * from post WHERE post.id in (123,456,314,141)
12、同数据类型的列值比较
•原则:数字对数字,字符对字符
•数值列与字符类型比较
同时转换为双精度
进行比对
•字符列与数值类型比较
字符列整列转数值
不会使用索引查询
举例:字符列与数值类型比较
13、Load data 导数据
• 批量数据快导入:
成批装载比单行装载更快,不需要每次刷新缓存
无索引时装载比索引装载更快
Insert values ,values, values 减少索引刷新
Load data比insert快约20倍
• 尽量不用 INSERT ... SELECT
延迟
同步出错
14、打散大批量更新
•大批量更新凌晨操作,避开高峰
• 凌晨不限制
• 白天上限默认为100条/秒(特殊再议)
• 举例:
update post set tag=1 WHERE id in (1,2,3);
sleep 0.01;
update post set tag=1 WHERE id in (4,5,6);
sleep 0.01;
五、约定类军规
1、隔离线上线下
构建数据库的生态环境,开发无线上库操作权限
• 原则:线上连线上,线下连线下
实时数据用real库
模拟环境用sim库
测试用qa库
开发用dev库
2、禁止未经DBA确认的子查询
MySQL子查询
大部分情况优化较差
特别WHERE中使用IN id的子查询
一般可用JOIN改写
• 举例:
MySQL> select * from table1 where id in (select id from table2);
MySQL> insert into table1 (select * from table2); //可能导致复制异常
3、永远不在程序端显式加锁
永远不在程序端对数据库显式加锁
• 外部锁对数据库不可控
• 高幵发时是灾难
• 极难调试和排查
幵发扣款等一致性问题
• 采用事务
• 相对值修改
• Commit前二次较验冲突
4、统一字符集为UTF8
•字符集:
MySQL 4.1 以前叧有latin1
为多语言支持增加多字符集
也带来了N多问题
保持简单
• 统一字符集:UTF8
• 校对规则:utf8_general_ci
• 乱码:SET NAMES UTF8
5、统一命名规范
• 库表等名称统一用小写
Linux VS Windows
MySQL库表大小写敏感
字段名的大小写不敏感
• 索引命名默认为“idx_字段名”
• 库名用缩写,尽量在2~7个字母
DataSharing ==> ds
• 注意避免用保留字命名
•举例:
Select * from return;
Select * from`return`;
更多文章,请关注公众号【程序员李木子】,有免费的电子书哦
