大厂真题之阿里云-Java实习生,面试记录整理
1、List 和 Set 的区别
List , Set 都是继承自 Collection 接口
List 特点:元素有放入顺序,元素可重复
Set 特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(元素虽然无放入顺序,但是元素在set中的位置是有该元素的 HashCode 决定的,其位置其实是固定的,加入Set 的 Object 必须定义 equals ()方法 ,另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。)
Set和List对比
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变
2、 讲一下常见编码方式?
编码的意义:计算机中存储的最小单元是一个字节即 8bit, 所能表示的字符范围是 255 个,而人类要表示的符号太多, 无法用一个字节来完全表示, 固需要将符号编码, 将各种语言翻译成计算机能懂的语言。
1)ASCII 码:总共 128 个, 用一个字节的低 7 位表示, 0〜31 控制字符如换回车删除等;32~126是打印字符, 可通过键盘输入并显示出来;
2) ISO-8859-1,用来扩展 ASCII 编码, 256 个字符, 涵盖了大多数西欧语言字符。
3) GB2312:双字节编码, 总编码范围是 A1-A7,A1-A9 是符号区, 包含 682 个字符, B0-B7 是汉字区, 包含 6763 个汉字;
4) GBK 为了扩展 GB2312,加入了更多的汉字, 编码范围是 8140~FEFE, 有 23940 个码位, 能表示 21003 个汉字。
5) UTF-16: ISO 试图想创建一个全新的超语言字典, 世界上所有语言都可通过这本字典Unicode 来相互翻译, 而 UTF-16 定义了 Unicode 字符在计算机中存取方法, 用两个字节来表示 Unicode 转化格式。不论什么字符都可用两字节表示, 即 16bit, 固叫 UTF-16。
6) UTF-8:UTF-16 统一采用两字节表示一个字符, 但有些字符只用一个字节就可表示, 浪费存储空间, 而 UTF-8 采用一种变长技术, 每个编码区域有不同的字码长度。不同类型的字 符 可 以 由 1~6 个 字 节 组成。
3、HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
不是线程安全的;
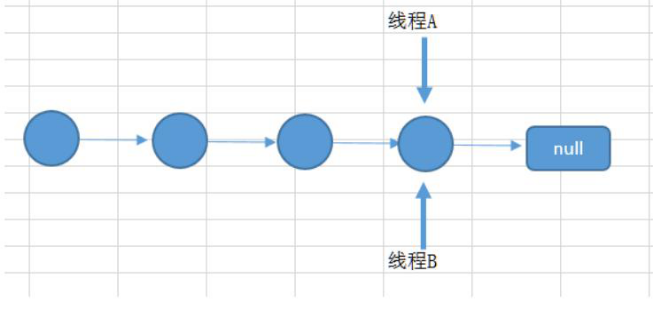
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位置还没有其他的数据。
所以这两个线程都会进入我在上面标记为1的代码中。假设一种情况,线程A通过if判断,该位置没有哈希冲突,进入了if语句,还没有进行数据插入,这时候 CPU 就把资源让给了线程B,线程A停在了if语句里面,线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if语句,线程B执行完后,轮到线程A执行,现在线程A直接在该位置插入而不用再判断。
这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线程不安全情况。本来在 HashMap 中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能就直接给覆盖了。
上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖住了前面添加的。

上面所说的是一个图来解释可能更加直观。如下面所示,两个线程在同一个位置添加数据,后面添加的数据就覆盖住了前面添加的。
如果上述插入是插入到链表上,如两个线程都在遍历到最后一个节点,都要在最后添加一个数据,那么后面添加数据的线程就会把前面添加的数据给覆盖住。则在扩容的时候也可能会导致数据不一致,因为扩容是从一个数组拷贝到另外一个数组。
4、HashMap 的扩容过程
cap =4, hashMap 的容量为4;
cap =5, hashMap 的容量为8;
cap =9, hashMap 的容量为16;
5、HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
HashMap结构图
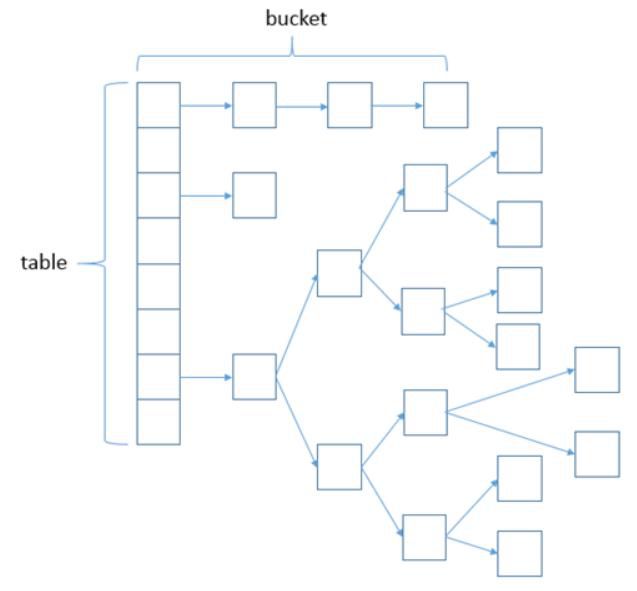
在 JDK1.7 及之前的版本中, HashMap 又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
JDK1.8 中,当同一个hash值( Table 上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。这就是 JDK7 与 JDK8 中 HashMap 实现的最大区别。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个 Entry 数组来存储数据,用key的 hashcode 取模来决定key会被放到数组里的位置,如果 hashcode 相同,或者 hashcode 取模后的结果相同( hash collision ),那么这些 key 会被定位到 Entry 数组的同一个格子里,这些 key 会形成一个链表。
在 hashcode 特别差的情况下,比方说所有key的 hashcode 都相同,这个链表可能会很长,那么 put/get 操作都可能需要遍历这个链表,也就是说时间复杂度在最差情况下会退化到 O(n)。
JDK1.8中
使用一个 Node 数组来存储数据,但这个 Node 可能是链表结构,也可能是红黑树结构
如果插入的 key 的 hashcode 相同,那么这些key也会被定位到 Node 数组的同一个格子里。
如果同一个格子里的key不超过8个,使用链表结构存储。
如果超过了8个,那么会调用 treeifyBin 函数,将链表转换为红黑树。
那么即使 hashcode 完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销也就是说put/get的操作的时间复杂度最差只有 O(log n)。
听起来挺不错,但是真正想要利用 JDK1.8 的好处,有一个限制:key的对象,必须正确的实现了 Compare 接口
如果没有实现 Compare 接口,或者实现得不正确(比方说所有 Compare 方法都返回0)那 JDK1.8 的 HashMap 其实还是慢于 JDK1.7 的
简单的测试数据如下:
向 HashMap 中 put/get 1w 条 hashcode 相同的对象
JDK1.7: put 0.26s , get 0.55s
JDK1.8 (未实现 Compare 接口):put 0.92s , get 2.1s
但是如果正确的实现了 Compare 接口,那么 JDK1.8 中的 HashMap 的性能有巨大提升,这次 put/get 100W条hashcode 相同的对象
JDK1.8 (正确实现 Compare 接口,):put/get 大概开销都在320 ms 左右
6、 谈谈你对解析与分派的认识。
解析指方法在运行前, 即编译期间就可知的, 有一个确定的版本, 运行期间也不会改变。解析是静态的, 在类加载的解析阶段就可将符号引用转变成直接引用。
分派可分为静态分派和动态分派, 重载属于静态分派, 覆盖属于动态分派。静态分派是指在重载时通过参数的静态类型而非实际类型作为判断依据, 在编译阶段, 编译器可根据参数的静态类型决定使用哪一个重载版本。动态分派则需要根据实际类型来调用相应的方法。
7、Java获取反射的三种方法
private int id;
String name;
protected boolean sex;
public float score;
}
//获取反射机制三种方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通过建立对象)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(所在通过路径-相对路径)
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
//方式三(通过类名)
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}
8、Java反射机制
public class ReflectTest {
public static void main(String[] args) throws Exception {
Class clazz = null;
clazz = Class.forName("com.jas.reflect.Fruit");
Constructor<Fruit> constructor1 = clazz.getConstructor();
Constructor<Fruit> constructor2 = clazz.getConstructor(String.class);
Fruit fruit1 = constructor1.newInstance();
Fruit fruit2 = constructor2.newInstance("Apple");
}
}
class Fruit{
public Fruit(){
System.out.println("无参构造器 Run...........");
}
public Fruit(String type){
System.out.println("有参构造器 Run..........." + type);
}
}
9、Arrays.sort 和 Collections.sort 实现原理和区别?
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
//void java.util.ComparableTimSort.sort()
static void sort(Object[] a, int lo, int hi, Object[] work,int workBase, int workLen){
assert a != null && lo >= 0 && lo <= hi && hi <= a.length;
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi);
binarySort(a, lo, hi, lo + initRunLen);
return;
}
}
TimSort 算法为了减少对升序部分的回溯和对降序部分的性能倒退,将输入按其升序和降序特点进行了分 区。排序的输入的单位不是一个个单独的数字,而是一个个的块-分区。其中每一个分区叫一个run。针对这些 run 序列,每次拿一个 run出来按规则进行合并。每次合并会将两个 run合并成一个 run。合并的结果保存到栈中。合并直到消耗掉所有的 run,这时将栈上剩余的 run合并到只剩一个 run 为止。这时这个仅剩的run 便是排好序的结果
10、LinkedHashMap 的应用
基于 LinkedHashMap 的访问顺序的特点,可构造一个 LRU(Least Recently Used) 最近最少使用简单缓存。也有一些开源的缓存产品如 ehcache 的淘汰策略( LRU )就是在 LinkedHashMap 上扩展的。
11、 说说你对 Java 注解的理解
注解是通过@interface 关键字来进行定义的, 形式和接口差不多, 只是前面多了一个@
public @interface TestAnnotation {
}
使用时@TestAnnotation 来引用, 要使注解能正常工作, 还需要使用元注解, 它是可以注解到注解上的注解。
元标签有@Retention @Documented @Target @Inherited @Repeatable 五种
@Retention 说明注解的存活时间, 取值有 RetentionPolicy.SOURCE 注解只在源码阶段保留,在编译器进行编译时被丢弃;RetentionPolicy.CLASS 注解只保留到编译进行的时候, 并不会被加载到 JVM 中。RetentionPolicy.RUNTIME 可以留到程序运行的时候, 它会被加载进入到 JVM中, 所以在程序运行时可以获取到它们。
@Documented 注解中的元素包含到 javadoc 中去
@Target 限 定 注 解 的 应 用 场 景 , ElementType.FIELD 给 属 性 进 行 注 解 ;ElementType.LOCAL_VARIABLE 可以给局部变量进行注解;ElementType.METHOD 可以给方法进行注解;ElementType.PACKAGE 可以给一个包进行注解 ElementType.TYPE 可以给一个类型进行注解, 如类、 接口、 枚举
@Inherited 若一个超类被@Inherited 注解过的注解进行注解, 它的子类没有被任何注解应用的话, 该子类就可继承超类的注解;
注解的作用:
1) 提供信息给编译器:编译器可利用注解来探测错误和警告信息
2) 编译阶段:软件工具可以利用注解信息来生成代码、 html 文档或做其它相应处理;
3) 运行阶段:程序运行时可利用注解提取代码
注解是通过反射获取的, 可以通过 Class 对象的 isAnnotationPresent()方法判断它是否应用了某个注解, 再通过 getAnnotation()方法获取 Annotation 对象
12、wait 和 sleep 的区别
public class Thread implements Runnable {public static native void sleep(long millis) throws InterruptedException;public static void sleep(long millis, int nanos) throws InterruptedException {if (millis < 0) {throw new IllegalArgumentException("timeout value is negative");}if (nanos < 0 || nanos > 999999) {throw new IllegalArgumentException( "nanosecond timeout value out of range");}if (nanos >= 500000 || (nanos != 0 && millis == 0)) {millis++;}sleep(millis);}//...}
public class Object {public final native void wait(long timeout) throws InterruptedException;public final void wait(long timeout, int nanos) throws InterruptedException {if (timeout < 0) {throw new IllegalArgumentException("timeout value is negative");}if (nanos < 0 || nanos > 999999) {throw new IllegalArgumentException( "nanosecond timeout value out of range");}if (nanos > 0) {timeout++;}wait(timeout);}//...}
-
1、 sleep 来自 Thread 类,和 wait 来自 Object 类。 -
2、最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。 -
3、wait,notify和 notifyAll 只能在同步控制方法或者同步控制块里面使用,而 sleep 可以在任何地方使用(使用范围) -
4、 sleep 必须捕获异常,而 wait , notify 和 notifyAll 不需要捕获异常
13、 Java 中 String 的了解
1) String 类是 final 型, 固 String 类不能被继承, 它的成员方法也都默认为 final 方法。
String对象一旦创建就固定不变了, 对 String 对象的任何改变都不影响到原对象, 相关的任何改变操作都会生成新的 String 对象。
2) String 类是通过 char 数组来保存字符串的, String 对 equals 方法进行了重定, 比较的是值相等。
String a = "test"; String b = "test"; String c = new String("test");
a、 b 和字面上的 test 都是指向 JVM 字符串常量池中的"test"对象, 他们指向同一个对象。
而new 关键字一定会产生一个对象 test, 该对象存储在堆中。
所以 new String("test")产生了两个对象, 保存在栈中的 c 和保存在堆中的 test。
而在 java 中根本就不存在两个完全一模一样的字符串对象, 故在堆中的 test 应该是引用字符串常量池中的 test。
例:
String str1 = "abc"; //栈中开辟一块空间存放引用 str1, str1 指向池中 String 常量"abc"
String str2 = "def"; //栈中开辟一块空间存放引用 str2, str2 指向池中 String 常量"def"
String str3 = str1 + str2;//栈中开辟一块空间存放引用 str3
//str1+str2 通过 StringBuilder 的最后一步 toString()方法返回一个新的 String 对象"abcdef"
//会在堆中开辟一块空间存放此对象, 引用 str3指向堆中的(str1+str2)所返回的新 String对象。
System.out.println(str3 == "abcdef");//返回 false
因为 str3 指向堆中的"abcdef"对象, 而"abcdef"是字符池中的对象, 所以结果为 false。 JVM对 String str="abc"对象放在常量池是在编译时做的, 而 String str3=str1+str2 是在运行时才知道的, new 对象也是在运行时才做的。
更多文章,请关注公众号【程序员李木子】,有免费的电子书哦
